3 ways to solve the agentic AI governance problem
The next wave of enterprise AI will be autonomous, persistent, and powerful. Whether you can deploy it in your environment depends on a question we don’t ask often enough: whose trust boundary does it ride inside?
The most exciting frontier in enterprise AI right now is also the most uncomfortable one. Autonomous agents (software that perceives, reasons, plans, and acts) have crossed from research demo to production-feasible in eighteen months. The capability is real. So is the governance gap.

The category-defining moment was OpenClaw, the personal AI agent that Peter Steinberger open-sourced earlier this year. Within weeks it became the fastest-growing repository in GitHub’s history. OpenClaw crystallizes the governance decisions every enterprise will now have to confront.
By design, OpenClaw runs locally on the user’s own device and, in its main session, gives the assistant full access when it is just you: host-level tool execution, file operations, browser control, scheduled jobs, the works.
For a developer running an AI assistant on their personal laptop for their own personal project, that may be the right design. It’s also the design pattern most viral agentic projects share: maximum capability, minimum constraint, trust derived from the fact that the operator and the user are the same person.
The trouble is that the design that’s correct for “just you on your laptop” inverts the requirements the moment an agent needs to act inside a regulated workplace. The technical achievement is striking. The enterprise readiness is a separate question.
Most CIOs and CISOs we talk to recognize the shape of the problem immediately. An autonomous agent with broad tool access isn’t a software question, it’s a principal. A new actor inside the trust boundary, executing on behalf of a human, often without the audit, identity, and approval scaffolding that every other actor in the enterprise has had to obtain.
So the executive question isn’t “should we deploy AI agents?” That ship has sailed. The real question is: whose trust boundary do they ride inside?
The governance problem
Every enterprise security model rests on three foundations: identity, authorization, and audit. We know who the actor is. We know what they’re allowed to do. We can prove what they did.
A naively deployed agent fractures all three. Its identity is a shared service account, or worse, a hand-rolled API key sitting in a developer’s .env file. Its authorization is whatever the credential happens to grant, usually far broader than the agent actually needs. Its audit trail lives in scattered tool logs, often without correlation back to the human who launched the task or the policy that approved it.
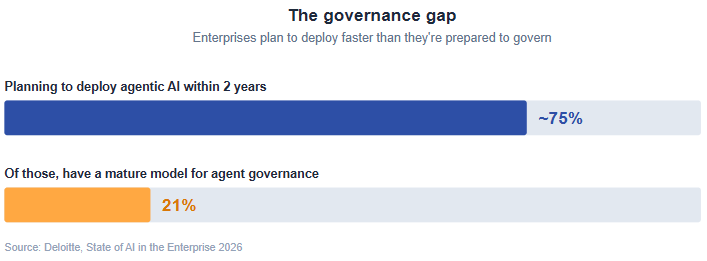

This isn’t a theoretical concern. The agentic systems generating the most attention right now: OpenClaw and the many projects following its pattern operate, by design, with maximum capability and minimum constraint in their main session. That’s appropriate for a personal-device assistant. It is unacceptable production risk in any regulated environments, healthcare, finance, government, and critical infrastructure.
Three agentic AI governance options
Enterprises have 3 options for solving agentic AI governance:
- Wait. Several large enterprises have done exactly this, deferring agentic work until the governance picture clarifies. It buys time but cedes ground to competitors who don’t.
- Build a parallel trust system around the agent. Net-new identity, authorization, and audit infrastructure dedicated to AI workloads. This is the path most “AI governance platform” vendors offer. It is technically possible, organizationally expensive, and slow. Every new system carries its own approval cycle, integration burden, and audit scope.
- Leverage existing trust boundaries, which is the one we find most pragmatic and is where the real architectural opportunity sits.
| Option | What it requires | Time to deploy | Risk profile | Best for |
|---|---|---|---|---|
| Wait | Defer agentic work until standards clarify | Indefinite | Competitive risk; productivity gains accrue elsewhere | Highly regulated environments with low immediate urgency |
| Build a parallel trust system | Net-new identity, authorization, and audit infrastructure | Quarters to years | High cost, separate audit scope, ongoing vendor management | Specialized AI workloads that genuinely fall outside existing platforms |
| Leverage existing trust boundaries | Extend an already-approved AI platform (Claude, ChatGPT Enterprise, Copilot) | Weeks to months | Inherits already-cleared identity, audit, and policy controls | Most enterprises with an approved AI platform in place |

The case for inheritance
Most large enterprises have already vetted, approved, and integrated at least one AI assistant into their environment, typically Claude, ChatGPT Enterprise, Microsoft Copilot, or a comparable platform. These systems went through real procurement reviews. They carry organization-level identity bindings (SSO, SCIM), administrator-controlled permission scopes, organization-wide data handling policies, and audit logging that integrates with the existing security stack.
That trust boundary already exists. The work has been done.
The question isn’t “can we approve agents?” It’s “can we deploy agents as a capability of a platform we’ve already approved, so they inherit its governance?” If yes, the path forward is short. If no, you’re back to building a parallel system.
This is not a marketing distinction. It’s an architectural one, with significant downstream consequences. When an agent operates as an extension of an already-approved AI workspace, several properties come along automatically:
- Identity is inherited. The agent acts under the user’s authenticated session. Every action ties to a real human identity, on the same SSO and MFA path that any other workplace tool uses.
- Permission scopes are policy-controlled. Tool access, data access, and network egress are all governed at the organization level by existing administrators, in the same console where they govern other policies.
- Audit follows an established path. Agent activity flows through the same logging, retention, and SIEM connections that already monitor the platform. No new pipeline.
- Data residency and processing terms are pre-negotiated. The legal review that cleared the AI platform for EU, healthcare, or regulated use extends to the agentic workload riding on top of it.
- Revocation is one switch. Disabling an employee’s account, or pausing the platform organization-wide, takes the agent with it. No orphaned credentials, no shadow access.
None of this is exotic. It’s the principle of least privilege, applied to a new kind of principal, by piggybacking on a control plane that’s already built.
What this looks like in practice: PACE
To ground the argument: at BETSOL we built and open-sourced an architecture we call PACE: the Persistent AI Context Engine, that demonstrates this pattern in working code. It’s a reference implementation, MIT-licensed and freely available on GitHub, that shows what agentic capability looks like when it’s deliberately constructed inside an existing trust boundary instead of around one.
PACE runs as an extension of Claude Desktop. That positioning is the entire point. Three capabilities sit on top of it:
- Persistent, tiered memory. A five-tier memory system: working memory, long-term memory, project memory, follow-ups, and archive. That lets an AI assistant accumulate genuine institutional knowledge across sessions instead of starting from zero each conversation. Memory lives on the user’s filesystem, under their own access controls, not in a vendor cloud the security team hasn’t reviewed.
- Routines. Scheduled agentic workflows that execute on a cron, such as daily scans, weekly synthesis, deadline tracking, and content reviews. All of this happens entirely within the permission scope the user already granted Claude Desktop. Nothing a Routine can do is anything the user couldn’t have done interactively.
- Proactive learning. Heartbeat actions where the assistant surfaces follow-ups, stale commitments, or patterns worth flagging, bounded by the same policy and audit envelope as every other action in the system.
The architectural commitment is consistent throughout: PACE adds capability, but it does not add a new principal, a new credential, a new audit pipeline, or a new policy surface. Every action it takes is an action the user could have taken themselves, executed under their identity, governed by their organization’s existing controls.
That design choice is unglamorous. It is also what makes the system deployable in environments that would never tolerate a sudo-equipped autonomous agent.
PACE at a glance
Apart from being enterprise governance ready, what does PACE give you?
- Remember everything
- Organizes and structures work (it doesn’t just answer questions and complete tasks)
- Creates “Routines” to proactively complete repetitive tasks
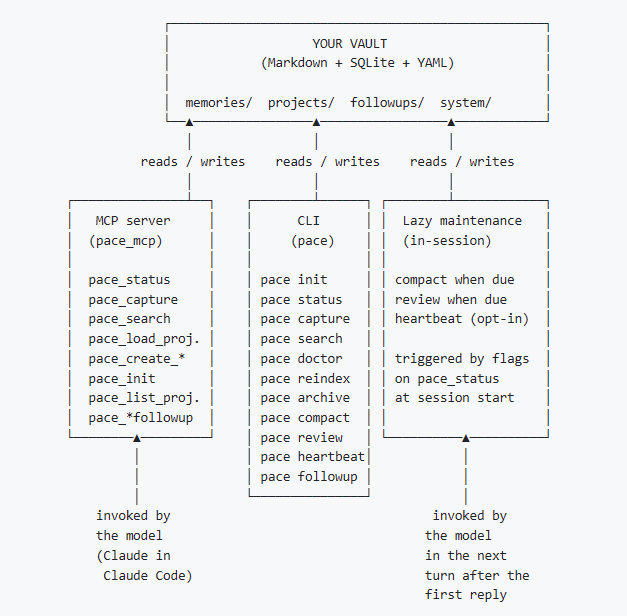
Architecturally, PACE is simple for humans to read and audit. It consists of markdown files, SQLite FTS5, and a Python-based MCP server. No cloud, no vector DB, no API keys. It functions entirely as a self-contained Claude Plugin.
Agentic AI governance as an architectural problem, not a policy problem
The deeper point is that AI governance will not be solved primarily through policy memos, vendor questionnaires, or new “AI committee” approval workflows. Those instruments are necessary, and they are not sufficient.
Governance scales when it’s encoded into architecture. The reason your enterprise can run tens of thousands of laptops without writing a policy memo per device is that those laptops inherit identity, encryption, MDM, and audit from systems built once and applied uniformly. The same will be true of agents. The organizations that move fastest in agentic AI over the next twenty-four months won’t be the ones with the largest governance committees. They will be the ones who recognized early which trust boundaries to extend and which to refuse to expand.
The practical implication for executives evaluating agentic projects right now is concrete:
- Ask where the agent’s identity lives. If the answer is “a service account we provisioned for it,” that’s a parallel trust system. If the answer is “the user’s existing organizational identity,” that’s inheritance.
- Ask where the audit trail goes. If it lives in a vendor’s proprietary logging system, you’ll be re-justifying it to your CISO every quarter. If it flows into your existing SIEM the same way the rest of the AI platform does, you’ve already cleared that bar.
- Ask what new permissions the agent is asking for. If the agent needs
sudo, unconstrained network egress, or its own long-lived API keys, you have a sudo problem. If it operates inside the same scope you’ve already granted for interactive AI use, you have an inheritance pattern. - Treat the agent as a feature of an approved platform, not a platform of its own. This single framing change typically shortens approval cycles from quarters to weeks.
Where this leaves us
Agentic AI is genuinely transformative. The productivity gains are not speculative. Early adopters are reporting them now, in production, in measurable terms. The barrier to enterprise adoption isn’t the technology. It’s the governance fit.
The good news: that fit is solvable, and it’s solvable through engineering choices most organizations can evaluate today. Choose architectures that ride inside trust boundaries you’ve already approved. Refuse to deploy agents that demand a parallel one.
At BETSOL we work with Fortune 50 customers on the production-grade end of this conversation. The systems that have to clear real audits, real compliance reviews, and real procurement gates. Our point of view is shaped by that work. Agentic AI is here. Deploying it responsibly is a design problem, and it’s one we’re glad to help our partners think through.
PACE is open source under the MIT license and available at github.com/jagbanana/PACE. To talk with our team about agentic AI governance and architecture in your environment, get in touch.


