If you’re running infrastructure management for your company, you’re well aware that any slip up in performance causes some serious problems for your company…and you. And the bigger your company, the more is at stake.
To put this in real terms, check out this graph that shows the cost of 1 hour of downtime by company size:
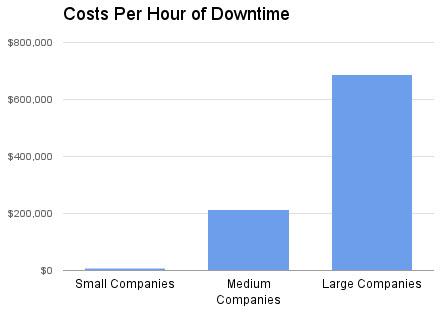
Source: Aberdeen Group – Downtime and Data Loss
While this is an average, there is a sharp difference between companies that do well and those that struggle.
Poor performers end up costing their business 40 times more per year than leaders. See all about these stats in my post 3 Ways to Benchmark Your Infrastructure Management.
But if you do things right, you can be the company hero. You can save massive amounts of money and keep your customers and internal stakeholders delighted.
So what does it take to be a leader in infrastructure management?
When you put together a roadmap that takes you from where you are today to a leadership position, consider the following:
- People
- Process
- Technology
Alright, with that said, check out these 7 tactics we regularly see across top performers, who not only spend less money but also perform massively better. We’ll touch on people, process, and the tech.
1. Leaders have employees with cross-platform technology knowledge
While laggards have specialists and rely heavily on individuals, Leaders take a different approach.
Leaders build a team that knows automation, monitoring, and proactive operations. The team has cross-platform application knowledge and is able to go wide before deep.
The employees sought have a deep understanding of architecture, virtualization, and inter-dependencies.
Here are some of the tools that help our people with a broad skill set keep a deep view of what’s happening in their environent:
Network monitoring tools that allow for a cross-platform view:
- Solarwinds: With its easy to use network mapping, Solarwinds is a standout winner. It enables us to monitor NetFlow, JFlow, sFlow, IPFIX, and NetStream. SolarWinds Server & Application Monitor provides more than 150 out-of-the-box application monitors.
- PRTG: Provides bandwidth monitoring using SNMP, WMI, NetFlow, sFlow, jFlow, and Packet Sniffing. It supports a huge set of notification technologies, including email, push messages, SMS/pager, Syslog, SNMP Trap, HTTP request, event log entry, alarm sounds, Amazon SNS, and external technology that can be triggered by an EXE or batch file. It also allows for distributed monitoring using remote probes.
These other tools help us operate in a cross-platform manner as well:
Backup:
Virtualization:
2. Leaders run 24x7x365 shops, rather than using on-call procedures
As you might be surprised, organizations often save money by switching from using on-call to having 24x7x365 operations.
The approach is to use offshore resources for out-of-hours and holiday support.
These teams can be performing critical tasks during out-of-hours, can address warnings before they become outages, and allow the core team to focus on strategic tasks.
Savings come from reduction in attrition, elimination of on-call pay, and several other buckets which are discussed in that post.
3. Leaders offshore a portion of infrastructure management
Infrastructure management often has very specific tasks that are best performed by a core team of employees.
However, much of the support is highly transactional in nature and can occur any time of day. These are perfect tasks to hand off to lower cost resources.
Additionally, partnering with an offshore company can immediately level-jump your up time results. Partners bring in best-practices and technology, shaving years off of learning curves for most organizations.
4. Leaders are focused on end-user experience
Leaders not only monitor application and node up time, but they also monitor entire process flows with end-to-end test transactions.
This allows complex issues to be identified before they impact end users. Also, it removes the “burden of proof” from the company’s employees and customers and shifts it to the infrastructure management team.
Think about it this way–does Amazon wait for customers to report that they cannot make a purchase on the site? Or do test transactions pick up issues first? If Amazon relied on customers to report outages anywhere in the purchase chain, millions would be lost in the blink of an eye.
5. Leaders leverage the right technology to proactively monitor
Tools available to infrastructure management teams address catching hardware warnings before they become failures, updating drivers and firmware automatically, and improving the scheduling and management of changes.
Business-rule tools allow teams to define thresholds and automation that will alert teams proactively of potential issues. Virtualization is also a key component of spreading risk and increasing redundancy.
Leaders in Infrastructure Support Organizations are aware of issues and address them before business impacts occur. This includes disciplines such as availability, security, patching, migrations, changes, and end-to-end test transactions.
Again, Solarwinds & PRTG are our go-to solutions here to keep track of:
- Applications
- Servers
- Available bandwidth
- Network parameters
- Usage and services
6. Leaders have efficient technology
Technology operates in a slim, virtualized, proactive environment.
Processes to manage this technology are repeatable, searchable, dummy-proof, checklist based, and updated in organic, ongoing manner.
- Make the technology deployment process repeatable – Moving from physical hardware to virtualization and building templates keeps operations repeatable, by-the-book, and error free.
- Eliminate single points of failure – Implement server, application, desktop, network, presentation, and storage virtualizations all using VMWare and Microsoft HyperV.
7. Don’t forget the biggest cause of enexpected downtime–hardware failure
Unnoticed hardware failure and outdated firmware/drivers are a major cause of unexpected down time. This is where the leaders focus, with the following tech in mind.
- Hardware monitoring tools like HP System Insight Manager and IBM System Director you monitor hardware health status. Also monitor the status of firmware and drivers by comparing it with a baseline in the management server.
- Enable automation and generate alerts to administrator, assigning tickets to the right team with tools such as Remedy. It can upgrade the firmware and drivers automatically.
- Automate the scheduling of changes through tools like Solarwinds, Spiceworks, and Palo Alto Panorama to generate alerts when uptimes reach defined thresholds. Build a rules engine that does the maintenance activities in predefined window of time.
Again, we use Solarwinds to monitor hardware failures. We have a regular patching program to make sure the firmware/drivers are up-to-date. Solarwinds includes performance, availability, and fault monitoring capabilities in one product. We can choose multiple modules together, or as individual standalone solutions. It provides dynamic and drillable network maps with real-time performance statistics.
Alright, is that a good enough sales pitch for someone else’s product? You can tell we’re believers.
Conclusion
Being a leader in terms of uptime provides massive value to your company. The roadmap you drive needs to include people, process, and technology. The technology is merely an enabler of the broad view your people and process will have.
What did I miss here? Is there anything you started doing at your company that level jumped your results?
